« Une seule chose coûte plus cher que
l’information…
L’ignorance » (J.F.K.)
L'histoire industrielle et celle des
sociétés sont ponctuées d'innovations techniques majeures ayant eu la capacité
de modifier les modes de production et d'échange, ainsi que de favoriser
l'émergence d'organisations sociales et politiques nouvelles en créant de
nouvelles normes de vie quotidienne. Ce sont par exemple : les moulins au Moyen
Age, l'imprimerie à la Renaissance, la machine à vapeur au XVIIIème siècle (1ère
révolution industrielle) ou l'électricité à la fin du XIXème siècle (2ème
révolution industrielle.). Actuellement, l'interaction croissante entre
plusieurs technologies de pointe comme l'informatique, la micro-électronique,
les télécommunications, les nouveaux matériaux, la biotechnologie et la
robotique profile l'aube d'une 3ème révolution industrielle.
La puissance d'accélération qui frappe
l'ensemble des processus industriels (mais aussi économiques) est actuellement
sans commune mesure avec celle produite par les précédentes révolutions
techniques. Alors qu'en passant d'une alimentation par la vapeur à une
alimentation à l'électricité, la mécanique avait gagné 40 fois plus de puissance
en 70 ans, le seul pouvoir des microprocesseurs a été multiplié par 1 million
durant les 40 dernières années (selon le principe de la loi de Moore qui stipule
un doublement de la capacité des microprocesseurs tous les 18 mois).
Cette révolution technique a envahi tout
l'espace de la microéconomie, aussi bien dans le fonctionnement des entreprises,
que dans la psychologie des consommateurs et l'attitude des individus face au
travail. Avec l'arrivée concomitante des services (développement massif du
secteur tertiare), de la notion de valeur immatérielle (marketing, design,
R&D, marque…), de la dématérialisation de l'économie (bourse) et
l'internationalisation des marchés, les NTIC (nouvelles technologies de
l'information et de la communication) ont fait basculer l'économie mondiale vers
un nouveau modèle de capitalisme ou plus précisément ouvert une nouvelle étape
de l'histoire économique. Un modèle qui modifie profondément tous les rôles
traditionnels des acteurs de l'économie dans ce qu'il est aujourd'hui convenu
d'appeler : la société de l'information.
Si l’information ne peut être mise en
cage sans perdre énormément de valeur, évidemment cela na signifie pas, biensûr,
que l’accès à l’information ne présente pas une richesse en soi. Et qui dit
richesse, dit concurrence et appétits divers pour y accéder, ou pour empêcher
d’autres personnes d’y avoir accès. C’est ce que savent depuis longtemps tous
ceux qui ont utilisé la rétention d’information en pensant y détenir une source
inépuisable de pouvoir.
Supposons donc, vous, heureux possesseur
d’une information, vous cherchiez à la capitaliser. Dans de très nombreux cas,
cette information va perdre très rapidement de sa pertinence, donc de la valeur.
C’est en particulier le cas de toutes les informations concernant la survenue
d’un événement pouvant avoir un intérêt d’ordre économique. Cette information
peut être utile à certains : elle a donc de la valeur, et peut donc être
monnayée. Si vous attendez quelques heures, voire quelques minutes, cette
information sera devenue sans valeur. Elle n’aura pas perdu un peu de valeur,
elle n’en aura plus du tout.
Les dirigeants d’entreprise, eux aussi,
doivent tenir compte de l’accélération du temps surtout lorsque ces informations
concernent leurs clients, ou leurs concurrents. Il s’agit de réagir encore plus
vite, avant que les informations dont ils disposent, en provenance de leurs
clients ou de leurs commerciaux ne deviennent obsolètes.
De l'intrusion électronique à la
recherche d'informations sensibles, en passant par l'Humint (renseignement
humain) l'intelligence économique trouve avec les NTIC de nouvelles clés pour
percer à distance les secrets et favoriser l'accès à des masses colossales
d'informations. Avec l'accessibilité apportée par le réseau Internet, la
confidentialité n'existe plus. Certains affirment que l'intelligence économique
va progressivement évoluer vers les techniques issues de l'espionnage, sachant
déjà que près de 80% des sources d'informations utiles sont «ouvertes» sur le
Net, c'est-à-dire libres d'accès.
Avec le Web, ses centaines de millions de
pages économiques et la prolifération des banques de données, le problème pour
l'intelligence économique n'est plus de trouver l'information mais de la
«traiter». Les tendances issues de l'intelligence économique évoluent de plus en
plus vers des systèmes «d'écoute informatique», de logiciels de captation
d'informations à distance, de logiciels d'analyse sémantique, de moteurs de
recherche conceptuelle capables de mouliner des millions d'informations et de
repérer les signaux faibles pour donner l'alerte. Autant de pièges émanant du
pot de miel, faisant que pour les nouveaux conquérants du Web, tous les coups et
contre-mesures sont permis entre stratégie, sécurité, légalité et illégalité.
Nous nous proposons donc d’analyser les utilisation de ces données et des enjeux
quelles représentent.
Les données auxquelles nous faisons
allusion sont exclusivement des données provenant de l’Internet. Nous cherchons
dans cette partie à définir le domaine d’étude et de rappeler certains concept
techniques constituant la base de notre analyse.
Une réponse simpliste à cette question
serait : toutes.
Mais il est nécessaire avant toute chose
de savoir dans quel but on souhaite obtenir ces informations.
Dans un but de revente directe ?
Dans un but de statistiques d’un site ? Ou encore dans un but de traitement
et de segmentation de la population (Ipsos, Iri Secodip , Nielsen
…) ?
Une étude de besoins est donc nécessaire
avant de commencer à réfléchir sur les stratégies et règles de gestion à mettre
en place.
1.
Pour revente directe ?
Dans ce cas, les informations les plus
intéressantes et faciles à négocier sont les informations nominatives sur des
personnes, telles que le nom, le prénom, l’adresse et l’e-mail. L’utilisation
finale de ces données est principalement à but d’envoi de masse à travers des
courriers ou le « Spam ».
Ces informations sont récupérées par des sites constitutionnels vitrine lors de
la demande d’information ou de la prise de contact.
2.
A des fin statistiques ?
Les informations retenues concernent
essentiellement la configuration de l’internaute (Navigateur,
Système d’exploitation, résolution) ainsi que ce que l’on appelle des
faits : L’instanciation d’une page à un instant donné. Toutes ces
informations permettent surtout de vérifier l’adéquation du site avec la
configuration des internautes mais aussi de savoir de quelle manière ils
parcourent le site.
3.
Pour segmenter la population ?
Dans le cas de recensement et de
segmentation de la population, les informations qualitatives sont mises en
avant. Elles comprennent les goûts, les loisirs, mais aussi les habitudes. Un
juste milieu est recherché entre la qualité et la quantité de ces informations.
Les informations nominatives sont aussi recherchées dans la mesure du possible.
Les sites permettant ce genre de récolte sont des sites d’e-commerce et de
communauté.
Exemple :
Alapage.com
Amazone.com
Caramail.com
Cette dernière stratégie est la plus
utilisée actuellement, car elle permet d’obtenir les meilleurs résultats au
niveau prédiction de comportement et donc de revente de cette information.
Un exemple plus flagrant est le site http://www.ConsoWinw.com de ConsoData. Il propose aux
internautes des bons d’achats sur des produits en échange de réponses à des
questionnaires.
Les entreprises de grande consommation
sont très intéressées par des études non quantitative comme par exemple des
enquêtes d’opinion ou de consommation (habitudes) mais aussi part les valeurs de
la population
1.
D’une manière directe
Lors de la navigation sur Internet, il
vous est sûrement arrivé de tomber sur un formulaire afin de bénéficier d’un
service quelconque.
Ce formulaire est le plus simple moyen de
récupérer des informations personnelles telles que le nom, le prénom, la date de
naissance et, bien évidemment, l’adresse E-mail. Mais il faut motiver
l’internaute pour qu’il consacre du temps à remplir un tel formulaire. Les
concepteurs de sites Internet ou d’applications Web jouent sur deux
paramètres : La taille du formulaire et le but du formulaire. Assurément,
plus la motivation de l’internaute est grande, plus le concepteur aura « le
droit » de demander des informations.
|

|
Par
exemple, lors de l’ouverture d’un compte d’adresse E-mail sur
« Caramail » ou sur « Hotmail », les formulaires sont
assez longs et portent aussi sur les loisirs et les centres d’intérêt. Le
but est assez conséquent pour répondre à ces questions, car l’internaute a
l’impression d’entrer dans une nouvelle communauté
gratuite. |
Par contre, lors d’une prise de contact
avec une institution telle qu’une Banque ou une assurance, le formulaire sera
très bref comme on peut l’observer à cette adresse : http://www.socgen.com/fr/html/aide/frame_contact.htm.
(cf annexes) Demander plus d’informations présenterait un handicap dans la
relation commerciale.
2.
D’une manière semi directe
Comme dans la vie "réelle", toute sortie
sur l'internet laisse des traces de votre passage (voir à ce propos la
démonstration en ligne sur le site de la CNIL http://www.cnil.fr/traces/index.htm). Votre façon de
surfer sur le web peut ainsi révéler un grand nombre d'informations concernant
vos centres d'intérêt, activités, voire (si vous vous inscrivez à des services
en ligne) le genre d'identités et mots de passe que vous utilisez probablement
sur d'autres comptes.
|

|
La
plupart des gens ne savent pas que l'ordinateur qui leur sert à surfer sur
Internet enregistre la majeure partie de ces informations. Mais, pour ceux
qui savent où regarder, il est relativement facile de retrouver
l'historique de tous les sites que vous avez visités, les fichiers que
vous avez téléchargés et autres informations auxquelles vous avez eu
accès. (Historique des navigateurs, cookies et
cache) |
Il existe d'autres façons de surveiller
votre utilisation du Web, comme les « cookies »
par exemple, qui, une fois implantés dans votre ordinateur par les sites que
vous avez visités, leur permettent de savoir combien de fois vous visitez leur
site et quelles sont les pages que vous avez consultées, entre autres
informations. La connexion établie entre votre ordinateur et serveur distant
peut aussi vous trahir et permettre à quelqu'un qui disposerait des
connaissances et du matériel nécessaires, d'enregistrer ce que vous faites sur
le « Cyberspace ».
Comme le montre le résultat du sondage
suivant, les cookies, ont une très mauvaise réputation, que l’on pourrait
qualifier de sulfureuse, car leur pouvoir d'intrusion a été sur-estimé pendant
de nombreux mois.
|
Aujourd'hui, vous percevez les cookies comme
: |
|
 49.8
% (239 votes) 49.8
% (239 votes)
Un usage abusif de vos données
personnelles
|
|
 32.1
% (154 votes) 32.1
% (154 votes)
Un moyen d'apporter des fonctions à
un site
|
|
 18.1
% (87 votes) 18.1
% (87 votes)
Je ne m'en soucie pas
|
|
Total
Votes: 480 |
Source : Journaldunet.com le 03/09/2001
3.
D’une manière détournée
Pendant l’explosion du marché des
start-up et de l’internet, beaucoup de personnes se sont posé des questions sur
le but et l’avenir de ces sociétés. La majorité de ces entreprises avaient deux
objectifs :
-
Un objectif de façade et une d’activité principale.
-
Un objectif réel : les données et leurs
exploitation.
Les exemples les plus flagrants
sont :
SprayDate : « Un service permettant de
faciliter au plus grand nombre d’internautes les rencontres amicales et/ou
amoureuses et de communiquer sur le WEB. Dans ce cadre, SprayDate propose
différents services disponibles sur son site regroupés sous l’appellation
LOVE@LYCOS (ci-après « LOVE@LYCOS) à l'adresse Internet
http://www.spray.fr/spraylove/, et notamment un service d'hébergement de pages
personnelles de présentation du membre, un service d'e-mails gratuit, un service
de discussions en ligne gratuit (chat) des Salons de Discussion
(Salons). »
BananaLoto : « La société Netarget, l'éditeur
de Bananaloto, rassemble des femmes et des hommes spécialisés dans leur domaine
(marketing, technique, finance, juridique…) et dont l'objectif est de vous
proposer un site ludique et agréable… mais aussi de vous faire gagner jusqu'à 10
millions de francs ! »
Ces deux sites proposent des services
louables vis-à-vis des internautes mais leur activité cachée est la manipulation
des données laissées par les internautes au cours de leur passage. Le diagramme
suivant, présent sur le site de Directinet montre le processus de
commercialisation des données de Lotree.com représente clairement les débouchés
de l’activité :
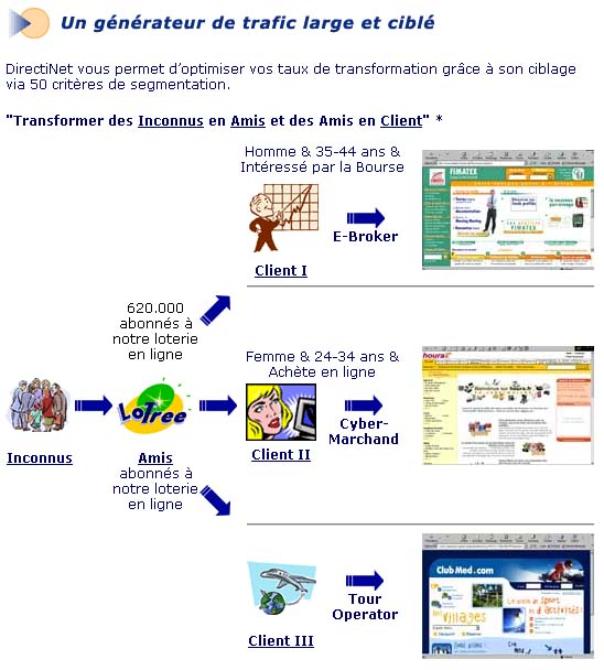
DirectiNet traite l’information afin de
segmenter la population et de revendre ces données à des clients précis.
La récupération de toutes ces
informations représente la mise en place d’une structure techniques assez
importante, c’est pour cela que nous donnons un aperçu de ces coûts et des
techniques. Elles sont illustrées dans l’exemple du site Jeujoo.com.
1.
Quand mettre en œuvre la récupération des
données ?
Le WebMining
contribue à augmenter les taux de transformation et la valeur du client qui sont
les deux variables clés sur Internet. En ce sens, il est incontournable pour
tous les sites arrivés à l’adolescence, c’est-à-dire ayant plus d’un an
d’ancienneté et une certaine réussite en termes de trafic et de ventes. La
plupart des sites d’une certaine ampleur ont déjà intégré ces technologies :
fnac.com, aucland, free, selftrade pour ne citer que quelques exemples.
2.
Contraintes
Les principales contraintes pour mettre
en oeuvre des techniques de webmining sont :
· La qualité des données collectées souvent douteuses soit
du fait des internautes eux-mêmes soit à cause de l’architecture technique du
site,
· La rentabilité économique, en particulier, pour la mise
en oeuvre des techniques de filtrage collaboratif encore coûteuses
aujourd’hui,
· Les contraintes de délais qui imposent dans l’Internet
de sortir des résultats rapidement, ce qui présente certains risques quant à la
pertinence des résultats.
3.
Coûts
Le coût de mise en place du webmining
varie fortement. Dans le cas de solutions de personnalisation en ligne en temps
réel, il n’est pas rare de comptabiliser les coûts en millions de francs, ce qui
explique finalement le faible nombre d’expériences menées en France à ce jour.
Le webmining offline, c’est-à-dire l’étude analytique des données issues du web,
s’assimile à du datamining sur le plan des coûts : de quelques dizaines de
milliers de francs à quelques centaines de milliers de francs selon l’ampleur
des projets ; ces coûts font que le point mort peut être atteint en B2B avec au
moins 20.000 entreprises environ tandis qu’en B2C, il faudra souvent plus de
100.000 clients pour pouvoir rentabiliser véritablement le webmining.
Après avoir mis ce genre de techniques en
place il est nécessaire d’augmenter son trafic et de bénéficier des données des
autres sites ou entreprises. Le Co-Branding correspond à cette attente.
1.
Définition
Cette technique vise à la mise en place
de pages mixant graphiquement deux marques distinctes qui s'associent le temps
d'une opération spéciale ou, à plus long terme, en vue de multiplier l'impact de
celle-ci grâce à l'addition de leur notoriété réciproque. Elle peut prendre la
forme de la combinaison de 2 logos ou de 2 contenus.
2.
Résultats attendus ?
a) Signal de qualité du produit et d'élargissement du
territoire
Plus qu'une garantie, le nom de marque
est un signe de qualité. Un nom de marque aide les consommateurs à comprendre
les caractéristiques de l'offre. Deux marques associées reflètent donc deux fois
plus de notoriété, de publicité et de confiance de la part des consommateurs.
Deux marques cohabitent pour renforcer la caution sur un produit et convaincre
le consommateur qu'une double signature représente bien plus de valeur que le
concurrent.
Le co-branding peut aussi permettre un
élargissement du territoire de la marque secondaire. L'alliance entre tf1.fr et
Mémopage.com illustre cet intérêt. Mémopage.com, fournissant des fiches de
révision pour le bac au site tf1.fr, tente de développer son territoire produit
et d'attirer les futurs clients car le site tf1.fr a beaucoup plus de trafic que
celui de memopage.com.
b) Transfert d'attributs symboliques et élargissement du
territoire
Qu'elle soit objective ou subjective,
l'information que les consommateurs possèdent sur une marque est transférée sur
les différents produits qu'elle signe, notamment comme marque secondaire.
Le co-branding représente une alternative
de la stratégie d'extension de marque et permet de développer la notoriété de la
marque. Le co-branding permet à la marque secondaire (invitée) d'améliorer sa
visibilité à un moindre coût, de pénétrer de nouveaux marchés et de recruter de
nouveaux acheteurs non-consommateurs ou sous-consommateurs de sa catégorie de
produit. Les consommateurs ont une meilleure évaluation d'un produit en
extension, lorsque celui-ci est issu d'un co-branding, que s'il émane d'une
stratégie d'extension de marque.
Hormis les avantages apportés par le
co-branding, il ne faut pas perdre de vue que la combinaison de deux marques a
pour règle élémentaire d'offrir un véritable " plus " aux consommateurs, et
qu'elle n'est pas sans risques pour les marques partenaires.
3.
Exemple
Milkado, site de jeux rémunérés, lance
une version ludique co-brandée accessible à partir du portail M6Net de M6. Le
jeu gratuit permet aux internautes de gagner de nombreux lots. Milkado devrait
prochainement livrer trois autres jeux aux sites M6.fr, M6music.fr et Funtv.fr.
Le site prévoit également de lancer une dizaine de versions différentes de son
jeu de jackpot ainsi que des interfaces en langue étrangère. Ainsi les deux
sociétés ont une relation gagnant-gagnant, Milkado bénéficie du trafic de M6Net
et M6Net bénéficie du contenu fournit par Milkado.
Nous abordons ce thème ici, car il est la
base de la majorité des utilisations ou techniques décrites plus loin. Nous
traitons le terme de DataWareHouse d’une manière simple, car nous focalisons
notre étude sur les usages des informations plus que sur les aspects techniques.
Nous considérons tous les types de données, y compris les données ne provenant
pas d’Internet car l’usage est le même : La provenance ou la nature des
données n’influence en rien le concept de DataWareHouse.
1.
Définition
Le concept de Data Warehouse a été
formalisé pour la première fois en 1990 par Bill Inmon. L’idée de constituer une
base de données orientée sujet, intégrée, contenant des informations datées, non
volatiles et exclusivement destinées aux processus d’aide à la décision fut dans
un premier temps accueillie avec une certaine perplexité. Beaucoup n’y voyaient
que l'habillage d’un concept déjà ancien : l’infocentre.
Mais l’économie en a décidé autrement.
Les entreprises sont confrontées à une concurrence de plus en plus forte, des
clients de plus en plus exigeants, dans un contexte organisationnel de plus en
plus complexe et mouvant.
Pour faire face aux nouveaux enjeux
économiques, l’entreprise doit anticiper. L’anticipation ne peut être efficace
qu’en s’appuyant sur de l’information pertinente. Cette information est à la
portée de toute entreprise qui dispose d’un capital de données gérées par ses
systèmes opérationnels et qui peut en acquérir d’autres auprès de fournisseurs
externes.
Actuellement, les données sont
sur-abondantes, non organisées dans une perspective décisionnelle et éparpillées
dans de multiples systèmes hétérogènes.
Pourtant, les données représentent une
mine d’informations. Il devient fondamental de rassembler et d’homogénéiser les
données afin de permettre l’analyse d'indicateurs pertinents pour faciliter les
prises de décisions.
Pour répondre à ces besoins, le nouveau
rôle de l’informatique est de définir et d’intégrer une architecture qui serve
de fondation aux applications décisionnelles : le DataWarehouse.
2.
Comment est structuré un datawarehouse ?
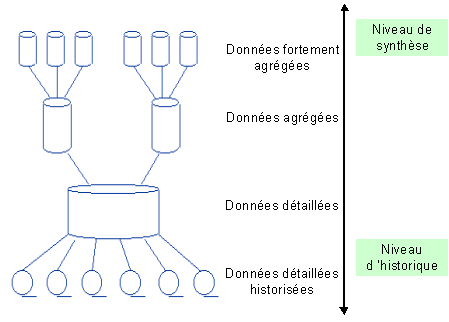
Un datawarehouse peut se structurer en
quatre classes de données, organisées selon un axe historique et un axe de
synthèse.
a) Les données détaillées
Elles reflètent les événements les plus
récents. Les intégrations régulières des données issues des systèmes de
production vont habituellement être réalisées à ce niveau.
b) Les données agrégées
Elles correspondent à des éléments
d’analyse représentatifs des besoins utilisateurs. Elles constituent déjà un
résultat d’analyse et une synthèse de l’information contenue dans le système
décisionnel, et doivent être facilement accessibles et compréhensibles.
Chiffre d’affaire, coût moyen, etc …
c) Les métadonnées
Très souvent les données à fédérer dans
le datawarehouse proviennent de sources très hétérogènes. Cela rend
indispensable la présence d'un dictionnaire unique qui sait gérer l'ensemble des
fonctions du datawarehouse. Cette cohérence du dictionnaire est décrite au sein
des métadonnées du dictionnaire du datawarehouse.
Les métadonnées constituent l'ensemble
des données qui décrivent des règles ou processus attachés à d'autres données.
Ces dernières constituent la finalité du système d'information.
d) Les données historisés
Chaque nouvelle insertion de données
provenant du système de production ne détruit pas les anciennes valeurs, mais
créée une nouvelle occurrence de la donnée.
3.
Quelles sont les méthodes ? Quels sont les
pièges ?
Actuellement, il n’existe pas de réponse
définitive à cette question.
|

|
Un
Data Warehouse est une solution spécifique, construite pour une
organisation. C’est pourquoi il peut sembler difficile de généraliser des
solutions adéquates pour tout Data Warehouse. Le paragraphe suivant à pour
objectif de tracer les grandes lignes et relais lors de l’élaboration d’un
datawarehouse. |
a) Les principes de base
Quoi ? Une
méthode basée sur le prototypage
Qui ? Les
acteurs
-
Les utilisateurs;
-
Les administrateurs de systèmes;
-
Les concepteurs.
b) La démarche de conception
Etape 1 : La justification et le
lancement du projet Data Warehouse
Le premier objectif de cette étape consiste en une étude
d’opportunité sur le développement du Data Warehouse. La décision de poursuivre
ou non le projet découlera de cette étude. Un premier recueil des besoins des
utilisateurs est effectué.
Etape 2 :
L’identification de l’existant et la conception de l’IHM
Cette étape a pour objectif de recenser les bases de données
physiques utilisées ainsi que leur contenu et leur gestion, afin d'établir un
premier niveau de description des informations indispensables à la création du
Data Warehouse.
Etape 3 : La
modélisation des systèmes opérationnels
Cette étape a pour objectif la modélisation des structures
de données opérationnelles en utilisant des techniques de rétro-ingénierie et
d’intégration de schémas.
Etape 4 : La
modélisation du Data Warehouse
Cette étape a pour objectif la conception de la structure du
Data Warehouse et de la métabase qui contient des informations sur les données
du Data Warehouse et des Systèmes opérationnels, ainsi que la description des
transformations à effectuer sur les données pour répondre aux besoins des
utilisateurs.
Etape 5 : La
modélisation du/des datamart(s)
L'étape de modélisation du Data Warehouse de l'entreprise
étant terminée, on peut en extraire un ou plusieurs modèle(s) plus orienté(s)
vers les différents départements (Datamart).
Etape 6 :
L’implémentation
Cette étape intervient après les étapes de modélisation du
data warehouse et du/des datamart(s) et a pour objectif l’étude des traitements
à réaliser sur les données ainsi que la création des processus de chargement et
de validation des données.
Etape 7 :
L’exploitation et l’évolution
Cette étape a pour objectif de mettre en place les
procédures de maintenance et de suivi du data warehouse et du/des datamart(s) ,
de mettre en production le data warehouse et le(s) datamart(s) et enfin de
mettre en production l’interface d’exploitation des données.
Cette méthode est conceptuelle et assez
difficile à réalisée rigoureusement dans le domaine Internet car elle ne prend
pas en compte les spécificité du réseau. De plus elle est assez coûteuse au
niveau des ressources humaines, ce qui peut représenter un obstacle à son
utilisation dans les petites sociétés Internet. Par contre pour des grands
compte qui possède déjà un DataWareHouse traditionnel, il est fortement
conseiller de l’étendre à l’activité du site Web.
La construction d’un DataWareHouse est la
base de tout traitement ou analyse futurs. Ces techniques, qu’elles
soient automatique ou manuelle, utilisent des procédés différents pour valoriser
l’information contenu dans le DataWareHouse.
Il semble aujourd'hui difficile de donner
une définition rigoureuse du data mining. Ce terme subit un effet de mode et
tout devient data mining. Le terme de Data Mining est souvent employé pour
désigner l’ensemble des outils permettant à l’utilisateur d’accéder aux données
de l’entreprise et de les analyser. Nous restreindrons ici le terme de Data
Mining aux outils et méthodes ayant pour objet de générer des informations
riches, de préférence à partir de données historisées, de découvrir des modèles
implicites dans les données. Nous nous proposons d’étudier l’ensemble des
techniques permettant de transformer l’information automatiquement.
Par contre, les outils d’aide à la
décision, qu’ils soient relationnels ou OLAP, laissent l’initiative à
l’utilisateur qui choisit les éléments qu’il veut observer ou analyser. Ce type
de logiciels sera étudié dans la partie suivante.
1.
L’environnement de l’entreprise
L’accroissement de la concurrence,
l’individualisation des consommateurs - la “démassification” - et la brièveté du
cycle de vie des produits obligent les entreprises à non plus simplement réagir
au marché mais à l’anticiper. Elles doivent également cibler au mieux leur
clientèle afin de répondre à ses attentes. La connaissance de son métier, des
schémas de comportement de ses clients, de ses fournisseurs est essentielle à la
survie de l’entreprise, car elle lui permet d’anticiper sur l’avenir.
Aujourd’hui, les entreprises ont à leur
disposition une importante masse de données importante (log, clients, commandes,
comportement). En effet, les faibles coûts des machines en terme de stockage et
de puissance encourage les sociétés présente sur Internet à accumuler toujours
plus d’informations. Cependant, alors que la quantité de données à traiter
augmente énormément - l'institut EDS estime que la quantité de données
collectées dans le monde double tous les 20 mois - le volume d’informations
fournies aux utilisateurs n’augmente, lui, que très peu. Ces réservoirs de
connaissance doivent être explorés afin d’en comprendre le sens et de déceler
les relations entre données et le comportement des internautes mal connu à ce
jour.
Dans cette optique, la constitution d’un
Data Warehouse comme présenté auparavant, regroupant sous une forme homogène
toutes les données du site sur une longue période, offre des perspectives
nouvelles aux décideurs, notamment en terme d’extraction de connaissances grâce
aux outils de Data Mining.
2.
Présentation du datamining
|

|
Les
outils de Datamining peuvent permettre par exemple à un cyber-magasin de
dégager des profils de client et des achats types et de prévoir ainsi les
ventes futures. Il permet d’augmenter la valeur des données contenues dans
le Data Warehouse.
Dans
le cas du Data Mining, le système a l’initiative et découvre lui-même les
associations entre données, sans que le décideur ait à lui dire de
rechercher plutôt dans telle ou telle direction ou à poser des hypothèses.
Il est alors possible de prédire l’avenir, par exemple le comportement
d’un client, et de détecter, dans le passé, les données inusuelles,
exceptionnelles. |
On pourrait définir le DATA MINING comme
une démarche ayant pour objet de découvrir des relations et des faits, à la fois
nouveaux et significatifs à la fois, sur de grands ensembles de données.
On devrait ajouter que la pertinence et
l'intérêt du data mining sont conditionnés par les enjeux attachés à la démarche
entreprise, qui doit être guidée par des objectifs directeurs clairement
explicités ("améliorer la performance commerciale", "mieux cibler les
prospects", "fidéliser la clientèle", "mieux comprendre les performances de
production"...).
On sait depuis longtemps procéder à des
classifications automatiques, construire et exploiter des modèles performants,
rechercher des corrélations entre variables... On connaît même dans bien des cas
l'incertitude attachée aux prévisions réalisées, ce qui permet de relativiser ou
pondérer les prises de décisions correspondantes (ce dernier point est aussi
essentiel que de déterminer les décisions elles-mêmes...).
On peut cependant faire aux méthodes
"traditionnelles" le reproche de ne pas avoir été vulgarisées. Le jargon
qu'elles utilisent, les outils mathématiques (mal connus du grand public) sur
lesquels elles s'appuient, les hypothèses préalables et validations requises
pour une mise en œuvre rigoureuse... sont autant de freins à un usage répandu de
ces méthodes.
Ces outils ne sont plus destinés aux
seuls experts statisticiens mais doivent pouvoir être employés par des
utilisateurs connaissant leur métier et voulant l’analyser, l’explorer. Seul un
utilisateur connaissant le métier peut déterminer si les modèles, les règles et
les tendances trouvés par l’outil sont pertinents, intéressants et utiles à
l’entreprise. Ces utilisateurs n’ont donc pas obligatoirement un bagage
statistique important. L’outil, donc, doit être ergonomique, facile à utiliser
et capable de rendre transparentes toutes les formules mathématiques et les
termes techniques utilisés ou bien il doit permettre de construire une
application “clé en main”, rendant à l’utilisateur transparentes toutes les
techniques utilisées.
Si des outils plus "récents", comme les
réseaux de neurones ou les arbres de décisions, connaissent un certain succès,
ils le doivent à leurs performances (dans certains domaines), mais probablement
aussi à leurs qualités de convivialité, liées à une terminologie souvent plus
accessible, à leur présentation résolument "pratique" et à l'occultation des
mécanismes et algorithmes internes qui les régissent.
Pour autant, les problèmes de mise en
œuvre, de compréhension des phénomènes et de validation des résultats
subsistent. Ils sont même dans une certaine mesure amplifiés par la simplicité
apparente de ces outils, qui n'incite pas toujours à la rigueur.
Une synthèse positive et optimiste des
différents outils et courants pourrait consister à améliorer la convivialité des
méthodes traditionnelles et à proposer un cadre méthodologique rendant plus
fiable et rigoureuse l'utilisation des outils plus récents.
3.
Le datamining et la recherche opérationnelle
La recherche opérationnelle n'est pas
assimilée aux techniques de Data mining. Son objectif est l'optimisation et la
recherche prouvée de la meilleure solution, ce qui n'est pas le cas du Data
mining :
· son champ d'application est plus large
· on ne recherche pas la meilleure solution prouvée mais à
faire le mieux possible,
· enfin un outil de Data mining appliqué à un même
ensemble de données ne donne pas toujours les mêmes résultats, contrairement à
la recherche opérationnelle.
4.
Statistiques et le datamining
On pourrait croire que les techniques de
data mining viennent en remplacement des statistiques. En fait, il n'en est rien
et elles sont omniprésentes. On les utilise :
· pour faire une analyse préalable,
· pour estimer ou alimenter les valeurs manquantes,
· pendant le processus pour évaluer la qualité des
estimations,
· après le processus, pour mesurer les actions entreprises
et faire un bilan.
Statistiques et data mining sont tout à fait
complémentaires.
L’intelligence artificielle et de
DataMining sont très proches car le dernier utilise le premier. Nous cherchons
ici à expliquer le principe de fonctionnement des moteurs de datamining.
1.
Les réseaux de neurones
Le cerveau humain est un système fort
bien adapté à la résolution rapide de problèmes en mode parallèle. Pour s'en
rendre compte, on n'a qu'à considérer le conducteur de voiture qui surveille sa
route, tout en changeant de vitesse et en continuant la conversation avec un
passager. Chacune de ces activités représente une tâche perceptuo-motrice
impressionnante en soi, consistant à interpréter visuellement et auditivement
l'environnement, tout en accomplissant les mouvements complexes et intégrés
soutenant la conduite de la voiture et la production de la parole. Pourtant, la
gestion parallèle de ces multiples tâches ne pose pas de problèmes excessifs à
la majorité des conducteurs expérimentés.
Le cerveau dispose d'environ 13 milliards
de neurones pour accomplir de telles tâches impressionnantes. (Les estimations
varient, certains auteurs parlant de 100 milliards), du point de vue
fonctionnel, le travail cognitif est effectué à une vitesse comparable à celle
de nos meilleurs émulateurs informatiques actuels (et souvent à une qualité
supérieure), et ce, malgré le fait que la transmission neuronale est
exceptionnellement lente. Aussi ce traitement s'effectue apparemment sans
itération ou récursivité.
On pourrait définir le réseau de neurone
comme « Un Processus opaque permettant à partir de
valeurs en entrée de découvrir une valeur en sortie. Les réseaux neuronaux sont
constitués de neurones, aussi appelés noeuds, et d'interconnexions entre ces
noeuds, liens permettant d'envoyer des signaux de neurone à neurone. Un réseau
de neurones a pour caractéristique de pouvoir apprendre et mettre à profit son
expérience pour ajuster le modèle trouvé en fonction, par exemple, de l'arrivée
de nouveaux éléments » (source : http://www.owil.org)
Les réseaux neuronaux représentent une
méthode de découverte des relations cause à effet. Contrairement aux méthodes
statistiques, un réseau neuronal ne présuppose pas obligatoirement une relation
linéaire entre les facteurs d’influence et les phénomènes prédits. Un réseau
neuronal a souvent besoin de moins d’observations que les méthodes statistiques
pour le développement d’un schéma prédictif.
Globalement les réseaux neuronaux sont
considérés comme un outil flexible et riche en applications possibles.
Cependant, cette même flexibilité rend souvent leur comportement imprévisible.
Avant d’appliquer une prédiction neuronale à un problème de prédiction, il est
sage de l’expérimenter sous de multiples conditions.
Les réseaux neuronaux se prêtent à de
multiples tâches telles que la distinction de différentes classes
d’observations, l’identification de nouveaux phénomènes et l’établissement de
relations cause à effet complexes.
C’est pour toutes ces raisons qu’ils
conviennent parfaitement pour traiter une masse de données importantes sur les
comportements des internautes. Il est ainsi possible de prédire le comportement
des internautes en fonction de ce qu’ils ont déjà fait sur le site et du chemin
de navigation qu’ils ont prit.
Cette technique peut notamment servir en
ergonomie et navigation de site. A partir des éléments de traces, des
statistiques peuvent êtres faites pour améliorer le déplacement dans le site ou
même orienter l’internaute.
Il serait intéressant d’appliquer une
telle expérience dans le cadre d’une démarche commerciale sur
Internet :
Rappelons tout d’abord les étapes de la
relation client lors d’une vente :
1. Présentation (mériter le
droit de poursuivre)
2. Démonstration des
savoir-faire et références (Déclaration de compétence)
3. Prise en compte des
besoins du « visiteur-prospect » et présentation de l’Offre
(Solutions)
4. Invitations
à rentrer dans une démarche pro-active en permettant et en encourageant la prise
de contact à tous les stades.(Services)
5. Donner de
l’information et en obtenir en retour
En associant la base de données de
chemins d’internaute ainsi que la démarche commerciale, il serait possible
d’orienter l’internaute vers les différentes étapes de la relation sans qu’il
s’en aperçoive. Le gain de réussite ou plutôt de transformation serait
accentué.
2.
Les réseaux bayésiens
Le principe de base d'un réseau bayésien
est celui d'un graphe au sens mathématique du terme, c'est-à-dire issu de
la théorie des graphes. Ce
graphe représente en un certain sens les relations entre variables en terme
causal, relations déterminées par des lois de probabilités conditionnelles,
elles-mêmes déduites des fréquences conditionnelles associées à un tableau de
données (Berry, 1998 ; Naim, 1999 ; Jensen, 1996).
Les réseaux bayésiens constituent une
alternative proche des réseaux de neurones.
3.
Un exemple d’utilisation sur le web
Les utilisations des données provenant de
l’Internet dans le domaine de l’intelligence artificielle sont rares mais
quelques sociétés commencent à y réfléchir.
L’exemple le plus marquant est celui de
la start-up Dipdop qui a lancé un assistant personnalisé dédié au conseil des
internautes indécis lors de leurs achats sur la toile. Celui-ci se présente sous
la forme d'un logo présent sur les sites partenaires (sites majoritairement sur
le marché des biens culturels). Lorsque l'internaute clique sur celui-ci il se
voit proposer des suggestions d'achats suite à une série de questions qui lui
seront posées. Ces questions, au nombre de 73, sont au libre choix de
l'internaute. Même s'il a répondu à une seule, le moteur sera à même de lui
faire des propositions. Evidemment, plus il y aura de réponses aux
questions plus
la pertinence des propositions sera élevée. Le logiciel génère ces propositions
à partir de croisements de profils contenus dans la base de données propre à la
société. Celle-ci a constitué pour sa phase d'amorçage, une base de 1.500
profils off line grâce à l'administration de formulaires sur une population
"représentative" d'internautes. La base contient également un large panel de
produits qui ne seront proposés que si le site marchand en question
commercialise ce produit.
Le logiciel d'intelligence artificielle
se fonde sur trois concepts :
· Logique floue (une situation donnée correspond à une
autre ou à plusieurs autres situations avec pondération des événements selon
leur importance).
· Réseau neuronal (pour tenter de reproduire la logique
humaine).
· Réseau collaboratif (c'est-à-dire le calcul des
propositions à émettre en se concentrant uniquement sur les informations des
internautes qui ont un profil proche du requêteur).
Le logiciel a été programmé en langage C++ et utilise une
architecture Pervasive/SQL. Le moteur est commercialisé en mode ASP (location
mensuelle) pour un montant aux alentours de 50.000F/mois, pondéré selon le
niveau de CA ou de trafic du site.
Selon Augustin Paluel-Marmont, directeur
marketing de la société, ce service supplémentaire permettrait d'augmenter le
taux de transformation sur un site de 0.5 à 1 point (le taux de transformation
moyen d'un site se situe entre 0.75 et 1.5%). Il s'avère particulièrement
efficace pour des sites positionnés sur le secteur culturel (voyages, cadeaux,
fleurs...) où les paniers d'achat ne sont pas trop élevés.
La société commercialise en parallèle des
études comportementales sur les profils des internautes (la base de profils
constituée au départ s'auto alimente au fur et à mesure que les internautes
sollicitent le moteur).
1.
Définition
Le principe du Push consiste à apporter
aux utilisateurs l’information de manière directe. Désormais ceux-ci n’ont plus
besoin de naviguer sur le réseau pour trouver les éléments dont ils ont besoin.
Il y a donc une opposition de nature entre le push et le pull, qui représente la
méthode classique d’utilisation de l’Internet.
Cette technologie introduit une forte
notion de personnalisation : chacun peut choisir et modifier à son gré la nature
des informations qu'il souhaite recevoir, ainsi que la manière dont il souhaite
les recevoir (fréquence des mises à jour par exemple)
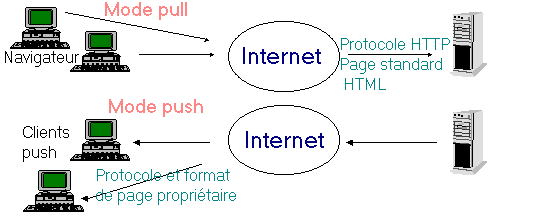
2.
Pourquoi le push ?
Il devient de plus en plus difficile de
trouver une information sur Internet. Certes, ce réseau propose des ressources
considérables mais l’information n’est pas structurée. La plupart des moteurs de
recherche réalisent des indexations sur la totalité du texte de chaque page.
Ainsi leur utilisation s’avère délicate et longue. Il est difficile d’obtenir un
nombre satisfaisant de réponses à partir d’une seule interrogation et le
problème ne fait que s’aggraver, car le réseau s’agrandit chaque jour. Le nombre
de machines connectées à Internet augmente de manière presque exponentielle. Il
sera probablement de plus en plus difficile de trouver la bonne information dans
cette énorme masse de données.
L’avantage premier du Push se fera dans
le marketing, car l’utilisateur est parfaitement ciblé. S'il lit un magazine sur
les nouvelles technologies et demande des informations sur les voitures, les
annonceurs d'automobiles et d'ordinateurs ou de téléphones cellulaires vont se
précipiter sur ce consommateur potentiel qui deviendra, tôt ou tard, un acheteur
réel. Ford, Nokia et Ibm vont donc promouvoir leurs nouveaux produits sur les
pages qui seront destinées à cette personne. Paradoxe de ce don désintéressé:
tout se paye... Le client est satisfait des données, en échange de quoi, son
profil est transmis aux annonceurs qui pourront mieux cerner ses demandes ; il
devient ainsi la proie idéale d'un matraquage publicitaire massif. Le danger de
cette omniprésence de publicité serait d'arriver à saturation. Ce matraquage
explique peut-être la prise de conscience des internautes sur les informations
privées qui circulent sur Internet. De même que l’excès d'infos tue l'info, de
même l’excès de pub peut entraîner un dégoût qui mènera à un boycott pur et
simple. Il ne faut pas oublier qu'Internet était, il n'y a pas si longtemps,
vierge de publicité et de commerce. Cette invasion est encore très mal perçue
par nombre de pionniers du Réseau à l'esprit communautaire très ancré.
Cependant aujourd’hui il est vital de
disposer rapidement de l'information pertinente et de l'avoir au bon moment.
C'est l'information en juste à temps. A partir de cette constatation est née aux
Etats-Unis une nouvelle technologie : La Push Information.
3.
Exemple de réalisation
Caramail.com, créé en 1996 par Orianne
GARCIA
était au début une messagerie en ligne gratuite permettant à quiconque de
posséder une adresse mail.
Depuis peu, le site caramail.com, étoffe son
offre et se transforme en une communauté grâce à des services personnalisés pour
ses internautes.
|
Choix des actualités voulues |
Caramail.com propose donc à sa communauté de remplir
un profil utilisateur. Ce profil est présenté sous forme ludique reprenant
l’astrologie chinoise, les métaphores sur les goûts et les couleurs. La
motivation première pour l’internaute est d’affirmer ses idées et sa
personnalité afin de rencontrer une personne ayant les mêmes centres
d’intérêts. |
Le communautaire a la possibilité de
s’inscrire ou de créer des forums de discussion sur des thèmes précis.
Le « Caramailien » peut aussi
personnaliser son portail d’accueil avec les informations qu’il désire : Le
programme de télévision, la météo d’une ville précise, les actualités dans tel
ou tel domaine. Tous ces services sont très utiles et recherchés, car il est
rare de trouver un site regroupant en une page toutes ces informations.
Le revers de cette communauté est
l’analyse poussée et la recherche de corrélation entre différents centres
d’intérêts afin de personnaliser les messages publicitaires et les bannières
tout au long de la navigation dans cet espace.
Un publicité ciblée sera nettement plus
rentable qu’une bannière placée sur n’importe quel site. Le pourcentage de clics
est multiplié, théoriquement par le nombre de centres d’intérêts que possède
l’internaute quand il visionne la publicité. Le coût de la bannière est lui
aussi incrémenté de la même manière. Ce principe de ciblage en fonction de la
personne connectée est un exemple de Push au service des annonceurs sans que
l’internaute s’en aperçoive.
4.
Proposition technique
Une étude Merise m’a permis de réaliser
ce modèle conceptuel afin d’héberger un système semblable à celui décrit plus
haut.
Le pré-requis à cette proposition est la
définition des centres d’intérêts que l’on souhaite répertorier mais il faut
aussi trouver les corrélations entre ceux-ci afin d’obtenir des profils types
d’internautes. Par souci de simplicité et de compréhension recherchés dans ce
document, on définira la corrélation entre deux centres d’intérêts au
maximum.
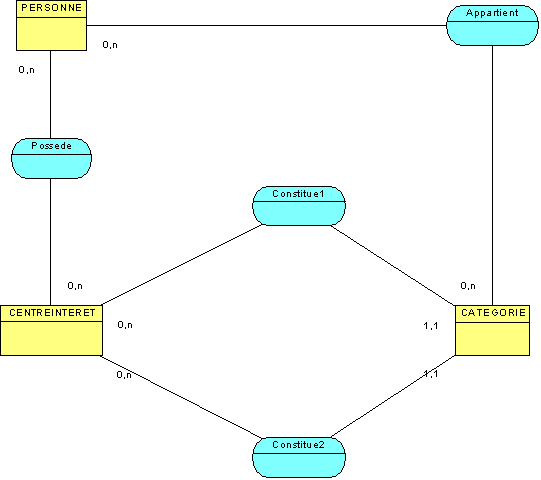
On retiendra deux étapes d’utilisation de
ce modèle :
· La première consistant à la récupération des centres
d’intérêts des internautes en créant une liaison entre un centre d’intérêt et
une personne.
· La seconde consistant à associer cette personne à des
catégories. Les catégories étant le rassemblement de deux centres
d’intérêts.
La redondance d’informations, dans ce cas
précis ne se présente pas comme un problème mais comme un atout
supplémentaire :
La redéfinition des catégories et la
ventilation des personnes dans des catégories peuvent se faire et se défaire à
volonté selon les mœurs, les indices sociologiques et la mode.
Le domaine de la prédiction automatique
du comportement de l’internaute est un sujet qui va devenir de plus en plus au
goût du jour. Les techniques deviennent de plus en plus fiables et offrent de
bons résultats.
Plusieurs obstacles restent
encore :
· Le coût de ces nouvelles technologies est très
conséquent car elles font appel à des chercheurs de haut niveau.
· Pour des raisons juridiques ces pratiques pourraient
relancer le débat sur la vie privée. Nous analyserons cet axe dans une partie
ultérieure.
· Enfin la conjoncture actuelle de l’économie sur Internet
peut freiner l’intégration de ces techniques.
C’est pour ces raisons que beaucoup
d’entreprises s’orientent vers des solutions intermédiaires moins
coûteuses : Les outils d’analyses manuelles.
|

|
Le
terme Business Intelligence a été introduit à la fin des années 1980 par
Howard Dresner, aujourd’hui spécialiste de ces questions au cabinet de
consultants américains Gartner Group. Il faisait référence à l’utilisation
d’outils logiciels par les cadres d’une entreprise pour accéder et
analyser des données, afin de prendre des décisions. La définition est
large et chacun peut y voir ce qu’il veut. Pourtant, il semble que trois
grands courants – au moins – vont se réclamer de l’appellation Business
Intelligence. |
La courbe suivante montre l’évolution de
la prise de valeur des systèmes décisionnels en fonction des avancées
technologiques dans le domaine.
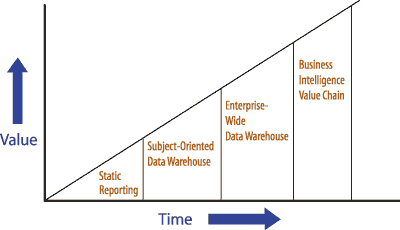
Courbe de valeur de l’intelligence économique
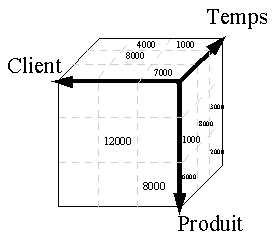
Ces logiciels servent à extraire d’une
montagne de données des informations pertinentes pour une direction. On retrouve
principalement dans cette catégorie les offres d’Ardent, Brio, Business Objects,
Cognos, MicroStrategy, Sterling Software. C’est le domaine des outils
sophistiqués, des moteurs OLAP (Online Analytical Processing) qui permettent à
l’utilisateur d’analyser rapidement des données qui ont été stockées dans des
structures multidimensionnelles. On peut ainsi facilement croiser des
informations complexes, toutes sortes d’incidences (régionales, saisonnières,
etc.) sur les chiffres de vente d’un produit.
Les systèmes décisionnels sont dédiés au
management de l'entreprise pour l'aider au pilotage de l'activité, et
indirectement opérationnels car n'offrant que rarement le moyen d'appliquer les
décisions. Ils constituent une synthèse d'informations opérationnelles, internes
ou externes, choisies pour leur pertinence et leur transversalité
fonctionnelles, et sont basés sur des structures particulières de stockage
volumineux Le
principal intérêt d'un système décisionnel est d'offrir au décideur une vision
transversale de l'entreprise intégrant toutes ses dimensions.
Afin de formaliser le concept OLAP, fin
1993, à la demande de Arbor Software, Edgar F. Codd publie un article intitulé
"Providing OLAP to User Analysts" aux Etats Unis, dans
lequel il définit 12 règles que tout système de pilotage multidimensionnel
devrait respecter..
"Ce qu’il y a
d’agréable avec ces outils OLAP", explique Eric Klusman, de Cantor
Fitzgerald LP, "c’est que je suis en mesure de distribuer
les données aux utilisateurs sans les obliger à apprendre des complexes formules
de programmation, d’interrogation ou même à ce qu’ils aient à programmer leurs
tableurs".
D’une façon générale, tous affirment que l’on peut interfacer de nombreux
outils d’utilisateurs avec des bases de données multidimensionnelles sans qu’il
soit nécessaire de consentir de lourds efforts de formation ou des interventions
importantes du service informatique.
Les années à venir vont très certainement
apporter de nombreuses modifications à ce schéma. Internet notamment vient
changer la donne. Un concept va fusionner le datawarehouse et le Web : il s'agit
du dataweb.
Le dataweb contient l'idée d'un accès à
une base de données universelle quelle que soit la plate-forme d'hébergement, sa
localisation ou le format de données. Il devient aujourd'hui essentiel d'avoir
accès aux données internes à l'entreprise, mais aussi aux données externes
provenant par exemple de l'Internet. Le dataweb sera accessible à partir d'une
application disponible sur toutes les machines, comme un navigateur Internet.
L'objectif est ici d'augmenter la qualité des décisions en augmentant la qualité
de l'information à la base.
De plus l'accès au dataweb sera possible
à partir de n'importe où dans le monde. A partir d'un ordinateur portable
l'utilisateur pourra travailler comme il le fait dans son bureau.
En parlant de l’activité internet,
Jean-François Variot, président d’ImageForce dit : « Internet offre également au marketing de nouvelles
observations et de nouveaux outils d’analyse du comportement des visiteurs et
des clients. L’intégration de données provenant du Web enrichit les politiques
de datamining et de segmentation qui en découlent. De simples émetteurs de
publicités, les marques se transforment en médias hautement connectifs, porteurs
de service et d’instrument d’écoute. »
Jean-françois Variot a notamment l’auteur
de l’ouvrage : « La marque post-publicitaire , Internet an
II ». Il est spécialisé dans l’intégration des schémas d’e-business avec
les circuits marchands traditionnels.
1.
Les sondages de mode et d’état
Ces sondages permettent d’étudier l’état
actuel d’un marché.
Les départements et les cabinets de
marketing sont très friands de ce type d’informations pour évaluer la réussite
d’une opération de promotion. Auparavant, ils avaient recours à des sondages et
à l’achat de ces données à l’INSEE.
Le budget dédié à l’acquisition des données représentait un part très importante
dans le coût total d’une étude marketing.
En découvrant les mérites du World Wide
Web, les cabinets de marketing se sont penchés sur cette activité.
Maintenant, il nous arrive souvent
pendant la navigation de répondre à des sondages sur nos préférences, l’activité
dans les entreprises ou nos modes de vie.
Par exemple, le site journaldunet.com,
propose chaque semaine un sondage sur l’activité internet. La population visée
par ces sondages sont les informaticiens, les directeurs informatiques ou
décideurs. Un des derniers sondages demandait le logiciel utilisé par les
Webmaster pour créer des sites web.
Le sondage a révélé :
50% Dreamweaver.
20% Visual Studio.
20% HomeSite.
10% Autres.
Ce type de sondage permet de jauger le
marché à un instant t. Il n’est pas rare que le même sondage soit répété
quelques mois après pour obtenir une évolution.
Ces études sont très prisées par les
éditeurs de logiciels. Ils peuvent ainsi connaître les futurs achats de leurs
logiciels.
2.
Les sondages de consommation
Ces sondages ont pour but de tester les
futurs produits sur un échantillon de population. Beaucoup de grandes marques
d’alimentation mettent en ligne des sondages pour obtenir un feedback sur leurs
produits.
Par exemple, Kellog’s a proposé à ses
internautes d’envoyer gratuitement des échantillons d’une nouvelle barre
céréalière (Nutrigrain) pour qu’ils puissent ensuite
donner leurs avis. Seules, les personnes qui avaient reçu l’échantillon
pouvaient répondre à ce sondage. Le feedback a permis de montrer que très peu de
personnes interrogées (<10%) aimaient le parfum fraise. Par contre, le parfum
chocolat remportait un fort succès.
Kellog’s a ainsi pu focaliser sa
production et son marketing sur le parfum chocolat. Le coût d’une telle étude
aurait été multipliée par 10 si elle avait été réalisée d’une manière classique
(démarchage à domicile ou dans les grandes surfaces).
De plus, Kellog’s possède maintenant les
adresses et renseignements sur les personnes interrogées. A la prochaine sortie
de produit il pourra les re-contacter afin de réaliser une nouvelle étude.
Dans ce cas, Internet a été utilisé pour
prendre contact, prospecter et réceptionner les feedbacks.
3.
Le ciblage de la vente
Comme le dit Jean-François Lepetit,
Président du Conseil des Marchés Financiers de First-e (Une banque virtuelle),
« Les établissements qui débutent sur internet n’ont pas
les mêmes pesanteurs qu’une banque traditionnelle, mais le plus important c’est
le client. Le coût d’acquisition d’un client est colossal par rapport à la mise
place de l’architecture d’un site Web. Qui plus est s’il faut garder ensuite ce
nouveau client très volatile ».
Cette citation montre l’importance de la
connaissance du client et du ciblage des offres commerciales.
La promotion d’un produit sur le web peut
se rapprocher du sur mesure et devenir interactive.
Toutes les écoles de management ont fondé
l’enseignement du marketing ces trente dernières années sur des raisonnements
issus principalement des marchés de consommation de masse. Or, si la
standardisation des produits et les économies d’échelle et de production qui
caractérisent la production de masse ne sont pas à remettre en cause, la façon
dont le produit est mis à la disposition du client va radicalement changer. Le
client attendra de plus en plus une démarche personnalisée (one to one), que
l’on vienne à lui, que l’on réponde à ses questions en le comprenant, et non
l’inverse.
La publicité et le marketing direct
doivent être nécessairement repensés pour le monde virtuel.
Le recrutement d’un client n’a plus le
même prix sur le net. La notion de fichier client n’a plus la même valeur.
Demain, le client ne supportera vraisemblablement plus d’être importuné par la
promotion d’un produit qui ne le concerne pas du tout. Pour toutes ces raisons,
l’entreprise doit donc repenser ses méthodes de marketing direct et de
communication commerciale auprès de ses cibles, et sa réactivité doit être sans
aucune mesure avec ce qu’elle était entre deux mailins annuels, une ou deux
campagnes publicitaires dans les supports traditionnels.
L’exemple caractérisant le mieux cette
idée est le site : Ooshop.com.
Ce site est le magasin en ligne de la
chaîne de distribution Carrefour. Il propose aux internautes d’effectuer leurs
courses sur internet et de se faire livrer. Après plusieurs commandes, une liste
des produits les plus souvent commandés est créée et proposée automatiquement
lors du choix des produits. Carrefour a ainsi su repenser ses techniques de
vente en faisant cohabiter ses techniques traditionnelles avec celles liées au
Web.
L’usage de toutes ces données, et le
profit que l’on peut en extraire, peut tenter plus d’une personnes à les
utiliser de manières abusives. C’est pour cette raison, qui nous semble
important d’étudier le sujet selon un axe juridique.
1.
Le bon sens
L'autorégulation par les acteurs
eux-mêmes est la voie préférée, même si nous doutons de son efficacité: nombreux
sont les professionnels qui prennent conscience de la nécessité de réguler le
réseau par la mise en place de solutions technologiques, de codes de bonne
conduite, la sensibilisation du grand public au fonctionnement et aux risques
d'Internet. Si Internet se veut un lieu autorégulé c'est parce que la
législation n'existe pas. Seule subsiste une morale éthérée définie,
paradoxalement, par les pirates informatiques à l'origine de l'E.F.F.
L'Electronic Frontier Foundation existe
depuis 1990. Elle a été fondée par MM. Mitch Kapor, fondateur du célèbre
logiciel de comptabilité " Lotus ", et John Perry Barlow, parolier du groupe de
rock " Grateful Dead " en réaction à une vaste opération policière menée par le
FBI contre le piratage informatique appelée " Sundevil ". L'EFF s'est donnée une
mission historique: " civiliser le cyberspace " en évitant le chaos et la
tyrannie.
Les farouches partisans du " Free Net "
adoptent deux présupposés:
-
la réelle capacité de l'utilisateur à pouvoir dissocier
l'information de la désinformation (voire de la manipulation) ;
-
la capacité à déceler ce qui est bien pour le netsurfer
de ce qui peut lui être nocif (psychiquement).
Pourquoi ces deux postulats ? Parce
qu'ils estiment que tout est bon, l'important étant l'usage que l'on en fait, à
l'image des hackers du Chaos computer club.
Herbert I. Schiller, professeur à
l'université de Californie s'inquiétait déjà des conséquences des avancées
technologiques en 1995: "En fait, une vérité simple s'est imposée: les
technologies les plus éblouissantes non seulement ne remplacent pas mais, au
contraire, peuvent dissimuler les faits concrets les plus élémentaires."
2.
 Des
outils pour devenir Anonyme
Des
outils pour devenir Anonyme
a) Navigation anonyme
Le but de la navigation anonyme est
d’agir comme un intermédiaire entre vous et les sites que vous visitez, en
dissimulant votre identité et en empêchant toute action visant à tenter de vous
suivre à la trace ou de recueillir des données sur vous.
Elle permet aussi de bloquer les
programmes qui peuvent causer des dommages à votre ordinateur ou prélever et
rassembler des données personnelles sur vous.
b) Envoi d’e-mail anonyme
Comme dans la vie courante, il est
possible d'envoyer un message sans y inclure une adresse de réponse, ni aucune
autre information sur votre identité (nom du serveur de votre fournisseur
d'accès ayant servi à l'expédition, etc.). Cela vous permet de parler plus
librement, sans craindre que vos propos, même un peu polémiques, n'aient de
conséquences pour votre personne.
c) Les sites proposant ces services
·
http://privacy.net/
·
http://anonymizer.secuser.com
1.
Les textes de loi
La loi la plus connue est celle relative
à l'informatique, aux fichiers et aux libertés: LOI N° 78-17 DU 6 JANVIER
1978
Article 1er
L'informatique doit être au service de
chaque citoyen. Son développement doit s'opérer dans le cadre de la coopération
internationale. Elle ne doit porter atteinte ni à l'identité humaine, ni aux
droits de l'homme, ni à la vie privée, ni aux libertés individuelles ou
publiques.
Article 2
Aucune décision de justice impliquant une
appréciation sur un comportement humain ne peut avoir pour fondement un
traitement automatisé d'informations donnant une définition du profil ou de la
personnalité de l'intéressé.
Aucune décision administrative ou privée
impliquant une appréciation sur un comportement humain ne peut avoir pour seul
fondement un traitement automatisé d'informations donnant une définition du
profil ou de la personnalité de l'intéressé.
Article 3
Toute personne a le droit de connaître et
de contester les informations et les raisonnements utilisés dans les traitements
automatisés dont les résultats lui sont opposés.
Article 4
Sont réputées nominatives au sens de la
présente loi les informations qui permettent, sous quelque forme que ce soit,
directement ou non, l'identification des personnes physiques auxquelles elles
s'appliquent, que le traitement soit effectué par une personne physique ou par
une personne morale.
Article 5
Est dénommé traitement automatisé
d'informations nominatives au sens de la présente loi tout ensemble d'opérations
réalisées par les moyens automatiques, relatif à la collecte, l'enregistrement
l'élaboration, la modification, la conservation et la destruction d'informations
nominatives ainsi que tout ensemble d'opérations de même nature se rapportant à
l'exploitation de fichiers ou bases de données et notamment les interconnexions
ou rapprochements, consultations ou communications d'informations
nominatives.
Elle régit le type d’informations que
l’on peut stocker informatiquement. Elle consiste à déclarer tout stockage
informatique à CNIL et à d’empêcher le stockage d’informations nominatives et
relatives à un comportement.
Dans les faits, elle pose des problèmes à
un détenteur de ces bases de données, car ces dernières sont soumises à des
changements de structure ou d’ajout de nouveaux types d’informations. Or la CNIL
ne possède pas les moyens financiers ni physiques de constater ces changements
par rapport à la déclaration initiale.
Outre cette astuce, la déclaration ne se
fait pas systématiquement :
Sur 100 sites de commerce étudiés,
55% n’ont pas été déclarés.
31%
n’affichent pas d’informations juridiques sur les données.
Source : Etude d'évaluation de 100 sites français de
commerce électronique – CNIL Avril 2000
2.
La jurisprudence et projet de loi
13 juin 2001 : le projet de loi "Société
de l'information" a été approuvé en Conseil des ministres.
Ce texte constitue une nouvelle étape
dans le processus d'adaptation du droit français à la société de l'information
qui s'est récemment traduit par la loi du 13 mars 2000 portant adaptation du
droit de la preuve aux technologies de l'information et relative à la signature
électronique et par le décret du 12 septembre 2000 modifiant le code des postes
et télécommunications et relatif à l'accès à la boucle locale.
Ce projet de loi, qui transpose la
directive européenne du 8 juin 2000 sur le commerce électronique, a pour
objectif essentiel de promouvoir la confiance dans les échanges électroniques et
de contribuer à la démocratisation de l'usage de l'internet.
Les principales dispositions du projet de
loi sont les suivantes :
-
Il favorise l'accès des citoyens à l'information sous
forme numérique ;
-
Il garantit la liberté de communication en ligne ;
-
Il clarifie le cadre juridique applicable au commerce
électronique ;
-
Il favorise le développement des réseaux numériques
;
-
Enfin, il renforce les moyens de lutte contre la
cybercriminalité.
Le texte complet du projet de loi peut
être lu à cette adresse :
http://www.legifrance.gouv.fr/html/actualite/actualite_legislative/prepa/pl_cnil.htm
3.
Que se passe-t-il à l’étranger ?
Une enquête consacrée au respect de la
vie privée sur Internet et à la personnalisation révèle des différences
transatlantiques.
Plus des deux tiers des Américains ne
souhaitent pas que le gouvernement prenne des mesures en faveur du respect de la
vie privée sur Internet, préférant une autorégulation de l'industrie à de
nouvelles lois. En revanche, selon l'enquête menée par Teradata, une division de
NCR (NYSE : NCR), à peine un tiers des Allemands sont en faveur de
l'autorégulation et préféreraient que le gouvernement prenne ses responsabilités
en imposant des contrôles du respect de la vie privée en ligne. Cette enquête
était menée pour le compte de Teradata par BuzzBack, un bureau d'études en
ligne.
En effet, ces deux pays sont très
préoccupés par le respect de la vie privée. Deux tiers (67%) des Américains et
une grande majorité (84%) des Allemands "pensent beaucoup
au respect de leur vie privée" quand ils surfent sur Internet.
"Si les sociétés
de niveau mondial qui souhaitent vraiment faire des affaires en ligne ignorent
la question du respect de la vie privée, elles le font à leurs risques et
périls" affirme Werner Sülzer, vice-président de Teradata pour l'Europe, le
Moyen-Orient et l'Afrique (EMEA).
Malgré les divergences d'opinion au niveau de
l'autorégulation et des réglementations gouvernementales, l’enquête, parmi
d'autres, révèle que les consommateurs se préoccupent du respect de leur vie
privée, tant sur Internet qu'offline. Ils souhaitent que les entreprises
prennent les mesures nécessaires afin d'établir un climat de confiance avec
leurs clients. Ainsi, si vous souhaitez gagner la confiance de vos clients, vous
devez respecter leur vie privée.
BuzzBack a mené une enquête quantitative
parmi près de 300 internautes américains et allemands au début du mois de mars
2001. Des groupes représentatifs de vingt internautes de chaque pays ont été
sélectionnés pour explorer le sujet en profondeur.
Tout en soulignant l'importance de gagner
la confiance des clients, l'enquête indiquait que la majorité des personnes
interrogées, tant en Allemagne qu'aux États Unis (soit 56% des Allemands et 80%
des Américains), seraient prêtes à donner des informations d'ordre privé en
échange de services plus personnalisés. Une majorité non négligeable des
personnes interrogées dans ces deux pays (soit 79% des Américains et 62% des
Allemands) ont déclaré que des garanties explicites sur la sécurité des données
personnelles les encourageraient à acheter des produits ou des services sur les
sites Web commerciaux.
L'enquête relevait, en outre, les
résultats suivants :
· Plus d'un tiers des deux groupes avait dépensé au moins
US$500 (DM1000) en ligne au cours des 12 derniers mois, la plupart du temps pour
des CD audio, des ordinateurs et des logiciels, des livres ou encore des
vêtements.
· Plus de deux tiers des deux groupes ont déclaré passer
de 10 à 50 heures chaque semaine sur Internet, la majorité précisant qu'ils
visitaient fréquemment de nouveaux sites Web.
· Malgré leurs inquiétudes sur le respect de la vie privée
en ligne, seuls 19% des Américains ont déclaré qu'ils lisaient toujours l'accord
de confidentialité des sites Web, comparés à 28% des Allemands. Par ailleurs,
62% des Américains et 50% des Allemands ont déclaré qu'ils lisaient "parfois"
ces accords. Quoi qu'il en soit, la présence d'un accord de confidentialité sur
les sites Web des sociétés inspire confiance à plus de 75% des Allemands et des
Américains.
· La majorité des Allemands et des Américains ont déclaré
que les sociétés associant la connaissance de leurs clients à la fois online et
offline offrent "un avantage qui simplifie la vie" (pour 56% des Allemands et
60% des Américains). Toutefois, 44% des Allemands et 40% des Américains se
disaient inquiets au sujet des sociétés qui en savaient trop à leur sujet.
EuroB2C structure son offre autour d’un
concept de publicité
interactive en associant un jeu-concours personnalisé et instantané, à un
spot présentant les savoir-faire de l’annonceur : Ce n’est plus l’annonceur qui
envoie l’information, c’est l’internaute qui, en jouant, accepte tacitement le
message associé au produit et à la prestation qu’il souhaite gagner.
EuroB2C propose à ses clients un outil centralisé qui leur
permet :
· De profiter, sur leur site, d’une offre globale pour l’organisation de jeux
concours ( inscriptions, règlement, techniques, sécurité) et l’exploitation des
données marketing obtenues.
· D’initier des synergies avec d’autres marques qui
partagent les mêmes cibles d’internautes, à travers le portail grand
public : Jeujoo.com.
EuroB2c apporte à l'annonceur sa
connaissance du jeu et des mécanismes de la publicité interactive, afin de lui
amener la
visibilité qu'il attend en lui permettant de communiquer de façon
ciblée.
EuroB2C propose évidemment des services autour de
cet outil et en particulier du conseil et de la réalisation des jeux et des
spots. Ils sont personnalisés pour nos clients afin de nous adapter à leurs
besoins de communication ( ponctuels ou récurrents ). Les savoir-faire en
graphisme et la créativité publicitaire d’EuroB2C permettent d’augmenter
l’impact et la force des campagnes de nos clients.
EuroB2C décline son concept en
commercialisant sa solution sous forme de marque blanche. Les
clients qui le souhaitent peuvent mettre en œuvre rapidement un jeu-concours
instantané, personnalisé et à forte portée marketing directement sur leur site,
lequel jeu sera relayé sur le portail jeujoo.com (exemple : jeu Passionata).
Eurob2C propose à ses clients une
connaissance précise des visiteurs en leur donnant accès en ligne aux données et
statistiques des internautes par l’intermédiaire de tableaux de bord.
Les clients peuvent enrichir les informations sur des internautes
déjà identifiés en leur posant des questions personnalisées.
EuroB2C offre également aux annonceurs la
possibilité de communiquer par l’intermédiaire de boîtes aux lettres
publicitaires spécifiques. Les envois se feront de façon ciblée grâce à une
base de données d’internautes qualifiés et consentants, lesquels
pourront à ce titre être rémunérés par l’annonceur. Cette offre nous permet
d’utiliser le push pour proposer un contenu aux internautes.
La stratégie et l’activité de notre société
s’appuient dans le domaine du BtoC et du BtoB sur les leviers d’Internet qui
sont l’interactivité par l’intermédiaire de processus transactionnel, les
techniques du pull par l’intermédiaire du site www.jeujoo.com et du push grâce aux boîtes aux lettres
publicitaires rémunérées, afin de constituer un contenu pour l’Internet à forte
valeur ajoutée.
Nous posons comme hypothèse de départ que
le site est déjà développé et en production. Le projet a donc pour but
d’intégrer la gestion de données à un pré-existant.
Nous réalisons ce projet par
incrémentation pour maîtriser les coûts et contrôler les possibles erreurs de
choix d’architecture ou de direction d’études.
|

|
Cette
étape consiste à fournir, à partir du concept décrit plus haut toutes les
informations possibles que l’on peut récupérer. Ainsi les bornes du projet
seront définies. Le livrable de cette étape comprenait un dictionnaire des
données récupérables. |
Pour chaque donnée nous avions les
paramètres suivants :
-
La manière de récupération
Comment peut-on obtenir ces données ?
La méthode était décrite en détail voire prototypée.
-
La pertinence de
l’information
Que permet-elle de connaître ?
Quelle est la durée de vie de l’information ?
Ce paramètre était documenté mais aussi évalué sur une
échelle de 1 à 10.
-
La volumétrie de l’information
pour 100 personnes
Ce paramètre sert plus tard afin d’évaluer les besoins
techniques mais aussi le coût financier.
-
Quelles sont les contraintes
techniques ?
Quelles sont les contraintes qu’engendre la récupération de
ces données ?
-
Le coût d’acquisition de la
donnée
Evaluer le coût d’acquisition d’une donnée est assez
difficile. Pour résoudre ce problème et fournir une cotation, nous avons retenu
le nombre d’heures ou de jours nécessaires pour mettre en place la récupération
de cette donnée. Cette quantité était multipliée par le coût journalier (Charges
de fonctionnement + Salaire) de la personne implémentant la récupération.
1.
Tri, analyse et choix des données
A partir de ce dictionnaire, il a fallu
trier ces données par ordre de pertinence, puis par coût d’acquisition. Pour
cela nous avons calculé le rapport suivant :

Représentation graphique du quotient pour
certains coûts d’acquisition.

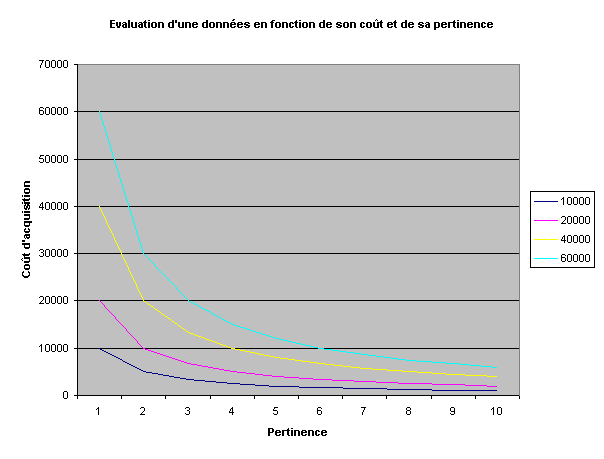
Ce graphique permet de définir une
fourchette de sélection des données. Dans notre cas, la fourchette retenue a été
de 0 à 15 000. Cela signifie que le coût d’acquisition par rapport à la
pertinence ne devait pas être supérieur à 15 000 F.
Cette technique permet de faire un
premier choix. Il est nécessaire, de jeter un coup d’œil aux données mises de
coté afin d’être sû de ne pas passer à côté d’une donnée fondamentale.
2.
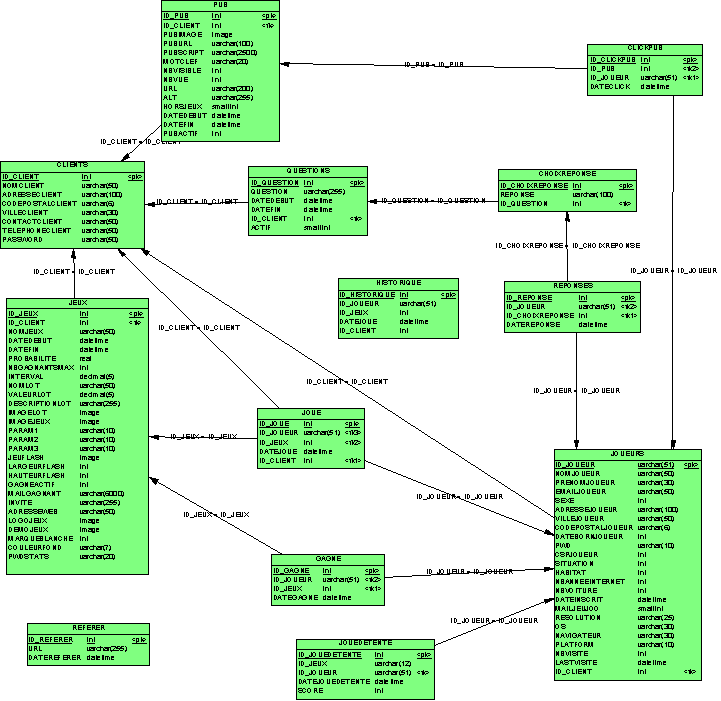
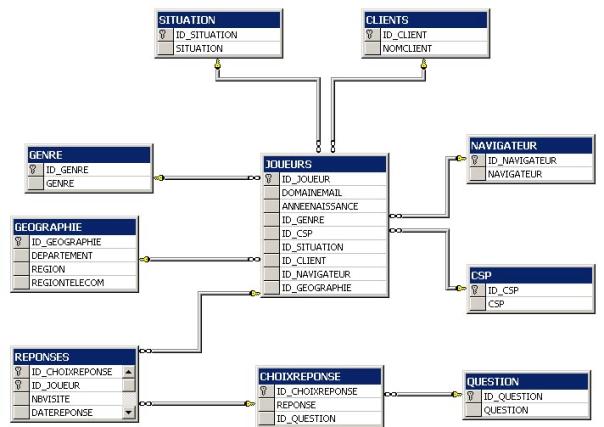
Modélisation de la base de données
La modélisation de la base a été réalisée
en appliquant MERISE. Nous avons retenu trois sous-systèmes :
· Les informations sur le joueur
· Les faits réalisés par les joueurs (jeux, gains, les
clics, provenance, dnslookup …)
· Les réponses aux sondages